
We’re reaching out to share an update to our Tag Monitor alert frequency.
What’s changing from today?
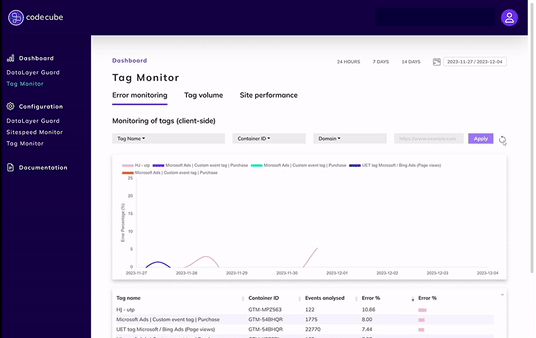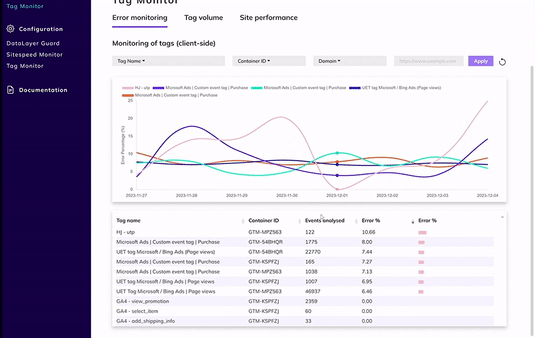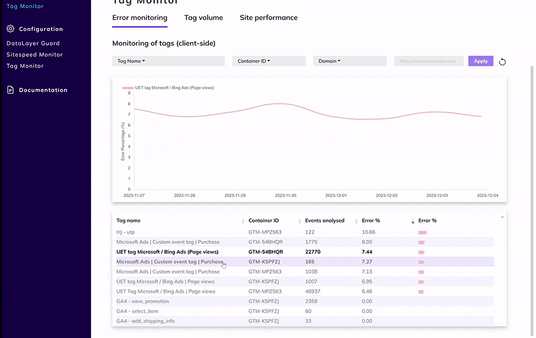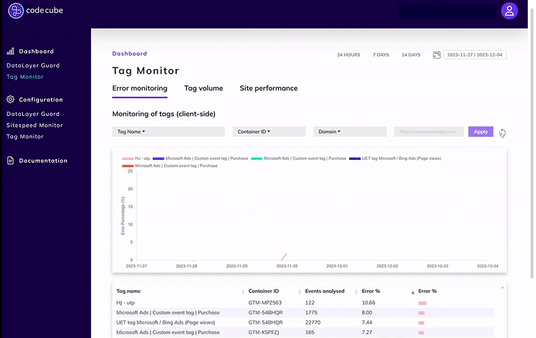
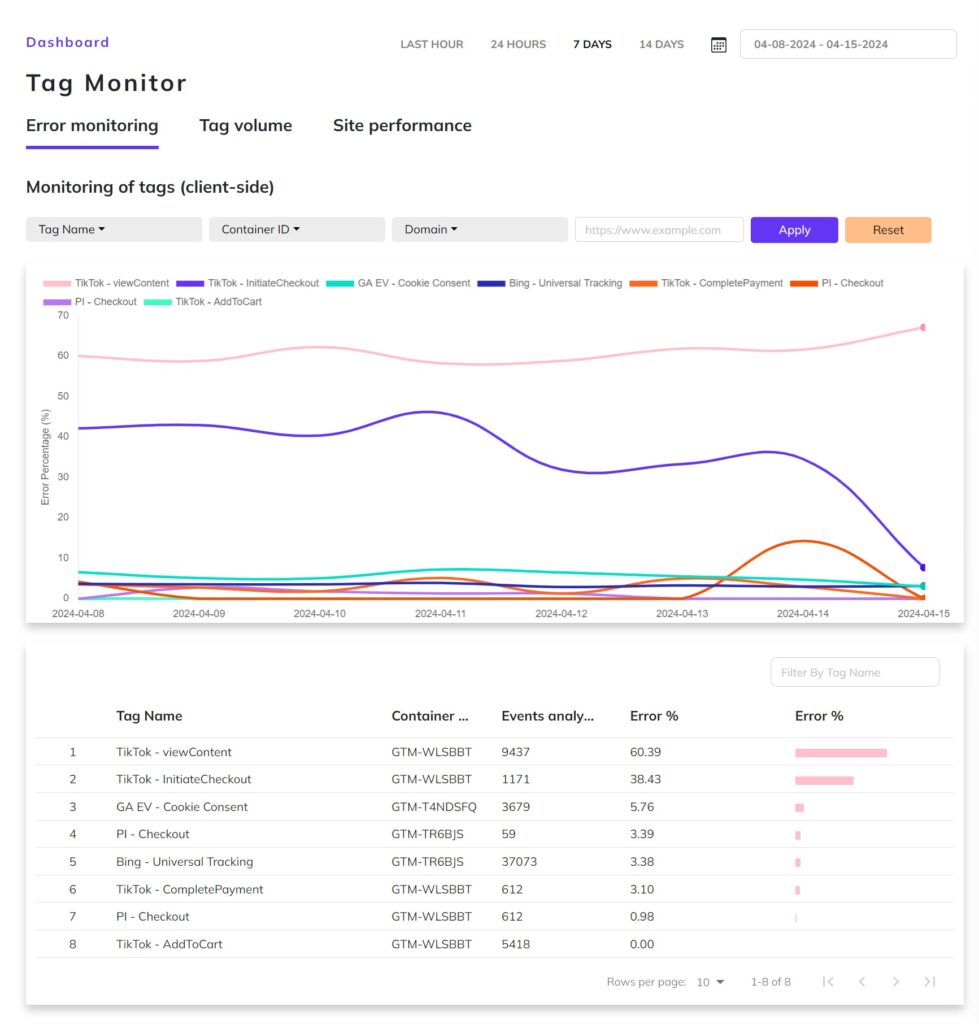
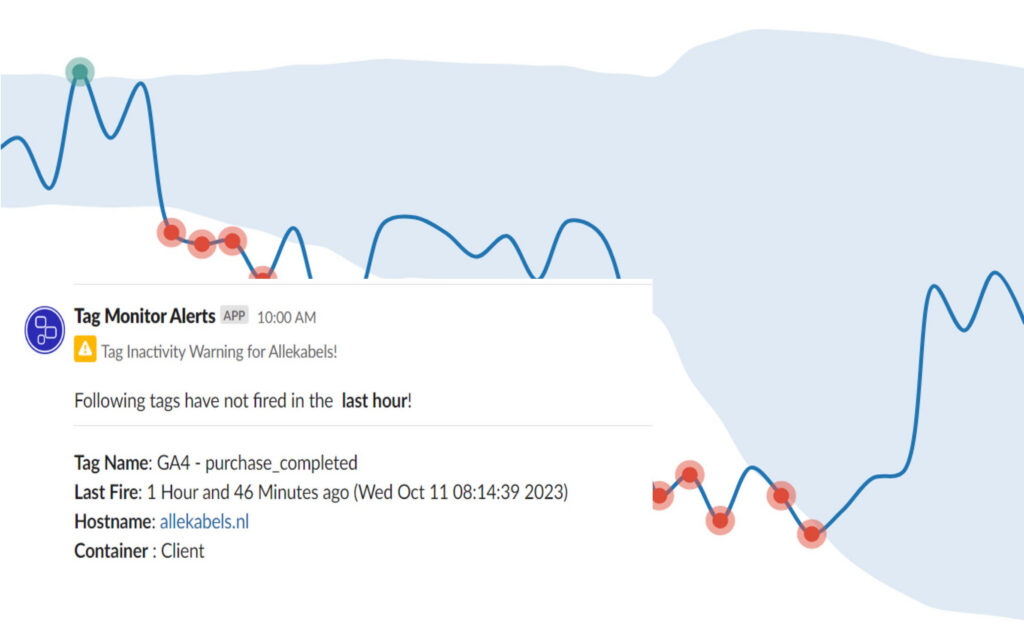
From today you’ll receive more focused Tag Monitor alerts, helping you stay on top of what truly matters:
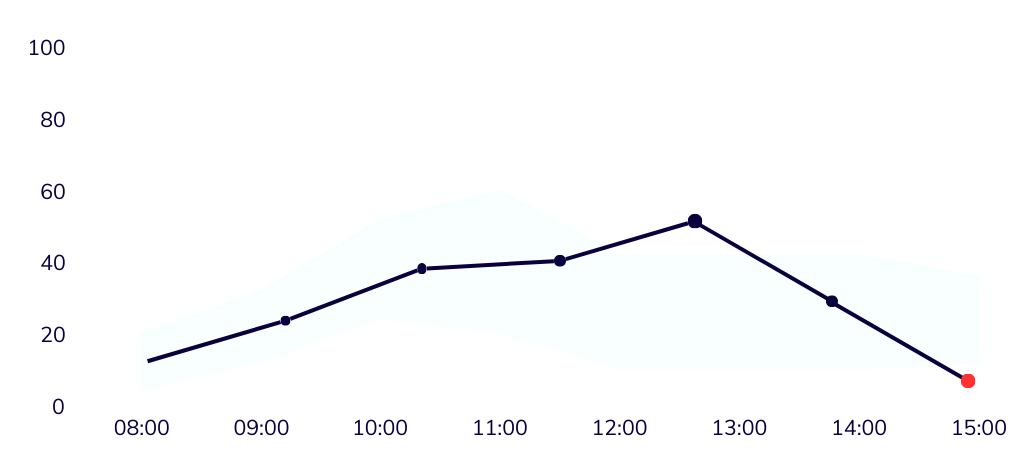
- Previously reported errors will no longer trigger daily repeat alerts;
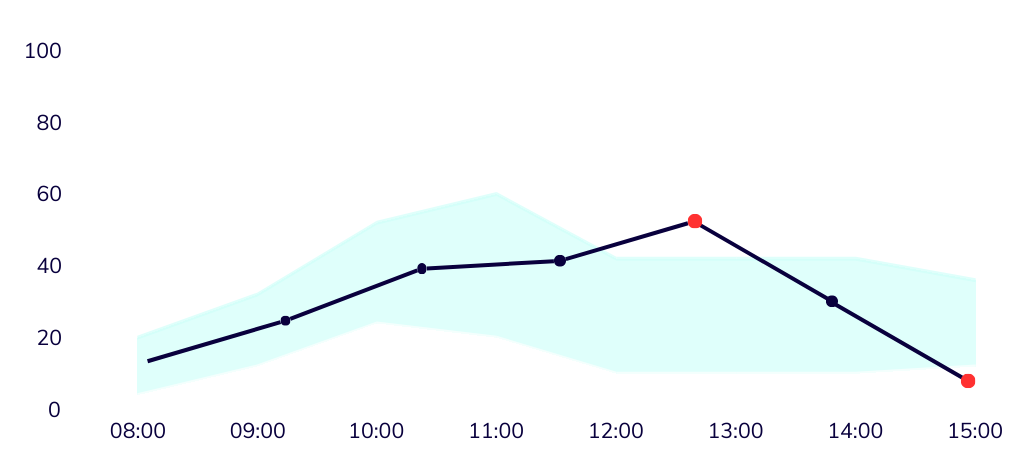
- You will only receive notifications for newly detected errors, or in case of a significant drop;
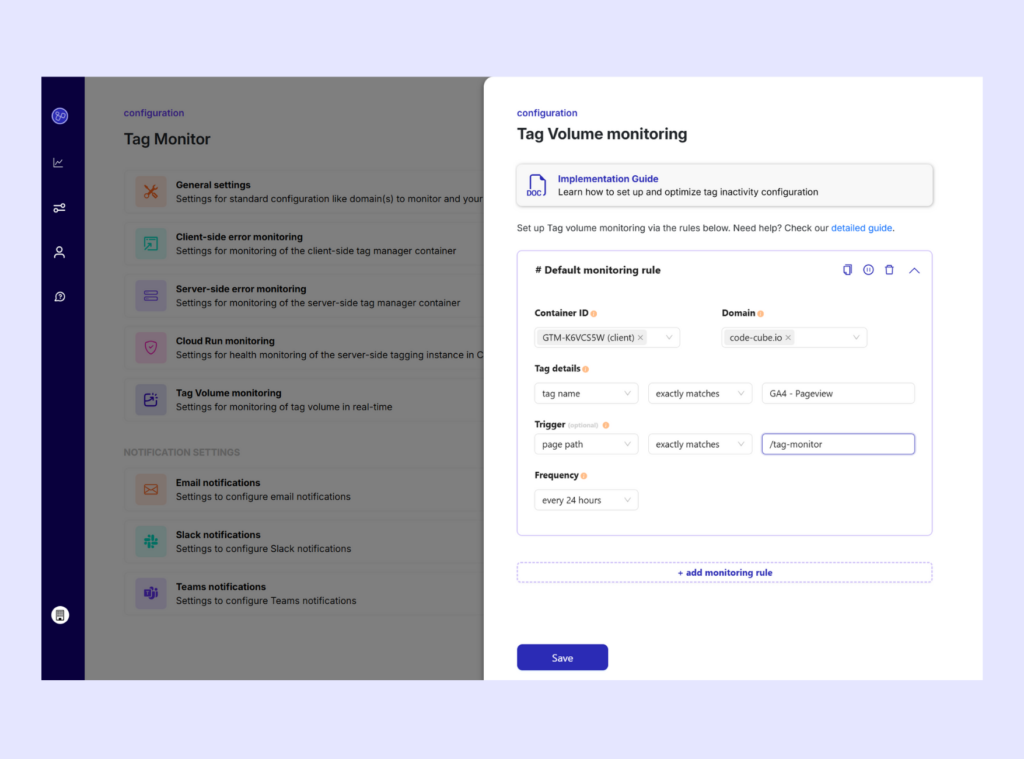
- The thresholds for a significant drop (default 10% absolutely- and 50% relatively) can be changed in the portal;
- A summary will be sent on a weekly basis.
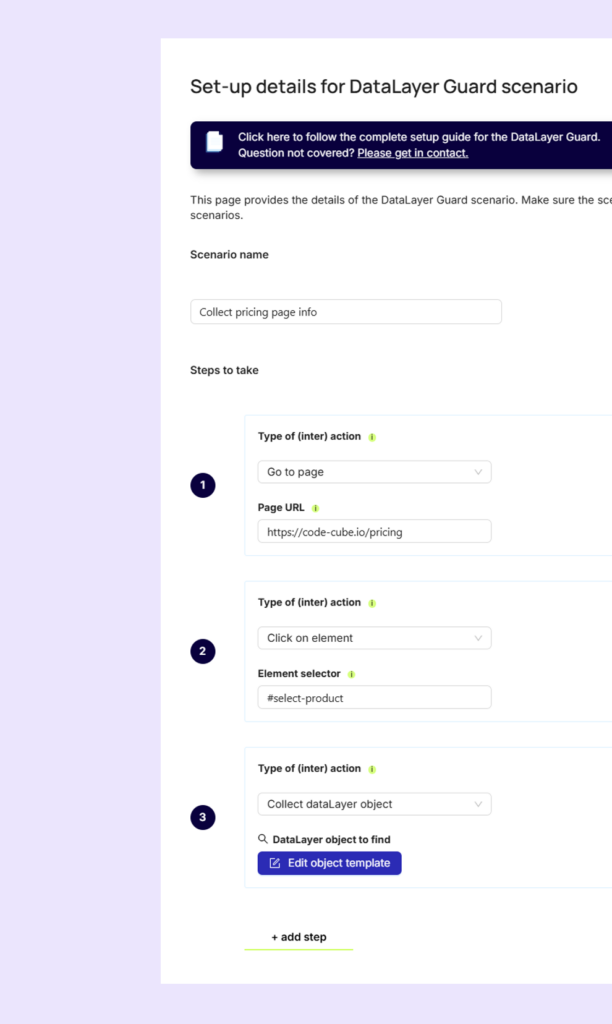
This change affects alerts via email, Slack, Microsoft Teams and other channels. If you previously set Tag Volume Monitoring to a 24-hour frequency due to email volume, you can now safely switch it back to hourly monitoring thanks to improved deduplication.
What else has changed?
Although we do not display or possess any privacy-sensitive data, we have added two-factor authentication (2FA) to the portal to add an extra layer of security when logging in.
What’s coming next
The AI Enricher provides diagnostic context for each tracking error, including its severity, the location of the error in your data collection, and recommended potential solutions based on similar historical patterns.
Currently it is being tested by a few selected customers and after that it will become available for Tag Monitor Premium and Enterprise users.
Thanks for using Code-Cube.io and if you have any questions about this update, we’re happy to walk you through it.